Imagine if you could drive to a car park and then, instead of spending 20 mins driving around trying to find a place to park, you tell your car to park itself. The car goes off and finds a spot. When you’re ready you summon it to come and pick you up. A bit like valet parking, except your valet is always with you when you drive.
2.5 years ago Parkopedia, the University of Surrey and the Connected Places Catapult set out to answer a question; how will autonomous vehicles park? We knew that this would be a difficult problem. Parking in a multi-storey car park means that there is no line of sight to satellites, which means no GPS. That said, GNSS (even RTK-GNSS) is not accurate in urban environments due to the canyon effect. As a result, a vehicle would need to estimate where it is using on-board sensors such as cameras, inertial measurement units and wheel odometry. We know that it’s possible to localise using LiDAR if a point cloud of the environment is available but LiDAR systems were very expensive. We chose therefore to focus on visual-inertial localisation.
Our goal was to work out what maps would be required to support the autonomous vehicle. We set out to develop the localisation and navigation algorithms that best utilise these maps and to prove them on our own autonomous vehicle. We had to ensure that any autonomous driving was done safely. Finally we wanted to find out what you, the general public, think of the idea of your car parking itself.
Project scope
The project scope was defined by these 5 objectives:
Developing automotive-grade indoor parking maps required for autonomous vehicles to localise and navigate within a multi-storey car park.
Developing the associated localisation algorithms – targeting a minimal sensor set of cameras, ultrasonic sensors and inertial measurement units – that make best use of these maps.
Demonstrating this self-parking technology in a variety of car parks.
Developing the safety case and prepare for in-car-park trials.
Engaging with stakeholders to evaluate perceptions around AVP technology
After the 7th quarterly meeting we published an update on the current status that showed that most of the work was complete. All that was left was to deploy the localisation and navigation software onto our autonomous StreetDrone test vehicle.
Demonstration
In the video above the software plans a route from the drop-off zone to the selected target parking spot when the driver presses ‘PARK’. Next, the vehicle localises itself by estimating its position with respect to the Artificial Landmarks. A recursive Bayesian Filter fuses the observations with odometry information . Finally, the software plans a path back to the pick-up zone when summoned.
With that demonstration we have completed all the deliverables for the AVP project and have successfully brought the project to completion on time and on budget! Our thanks go to
Throughout this project we learned that drivers value the convenience promised by cars that will park themselves. This project has delivered a major breakthrough by identifying and overcoming obstacles to full deployment of AVP through the development of a technology demonstrator. At some point in the next few years your car will be able to park itself and we’ll be proud to have played a role in making that happen!
Two years ago Parkopedia joined the Autoware Foundation as a founding member. With that short space of time all the necessary software for a full-scale AVP demo has been developed and tested. Automated Valet Parking (AVP) is the ability of a vehicle to park itself and to return to the driver when summoned.
The Autoware AVP was a complete success! Parkopedia is proud to have supplied the map of the AutonomouStuff car park in San Jose, CA where the demonstration took place. Parkopedia also supplied the path planning software that plans the route the vehicle will travel. In this case from the drop-off zone to the desired parking spot and back to the pick-up zone.
This is further confirmation that Parkopedia’s high definition digital maps are indeed suitable for navigation of automated vehicles inside car parks.
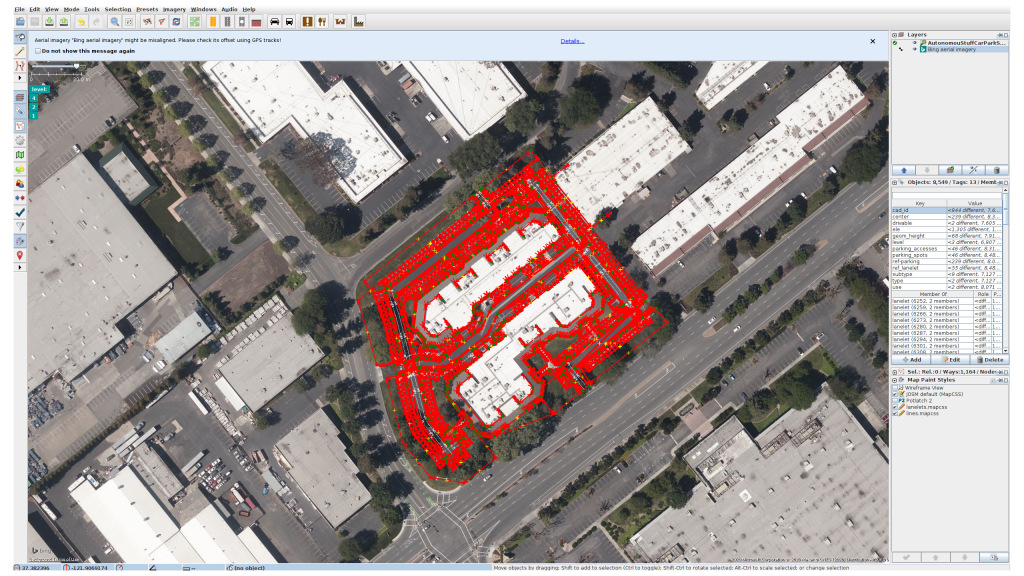
AutonomouStuff car park map in OpenStreetMap format
As Dejan Pangercic writes; “The demonstration itself was the culmination of a week of intense effort from contributors around the world, working around the clock to put the finishing touches on the low-speed maneuvers needed to accomplish the park and retrieve functions. The flawless performance highlights the engineering quality built into the ground-up design of the open-source Autoware.Auto software stack, intended to serve as a strong starting point for companies developing autonomous systems for commercial, mission-critical, or safety-critical uses.”
Congratulations to the entire Autoware team for all the hard work that has paid off handsomely!
The Autonomous Valet Parking (AVP) project is a 30 month project funded by InnovateUK and the Centre for Connected and Autonomous Vehicles. It is scheduled to finish on 31 October 2020.
With more than three-quarters of the project timeline having passed, we are proud to say that we feel on track to achieve the project objectives within the allocated project time allowance, even with the current additional challenges of COVID-19 self-isolation restrictions.
Over the 5 objectives, the current status is as follows:
Develop automotive-grade indoor parking maps required for autonomous vehicles to localise and navigate within a multi-storey car park. Parkopedia believes this map-based approach is the best way to achieve global scale for the roll-out of an Automated Valet Parking feature, which is likely to be the first SAE level 4 feature. This goal is 100% achieved, as Parkopedia has collected data in a number of car parks around Europe and is creating an inventory of maps to be able to supply to customers. Some of these maps have been made available to the research community under a Creative Commons license.
Develop the associated localisation algorithms, targeting a minimal sensor set of cameras, ultrasonic sensors and inertial measurement units, that make best use of these maps. We have agreed to use Artificial Landmarks in the final demo for the project, and toward that effort this goal is 95% complete. Details about Artificial Landmarks and how they can be used for localisation are available in this blog post. For the remainder of the project the research effort will be directed towards localising with natural landmarks which is a much more difficult problem.
Demonstrate this self-parking technology in a variety of car parks. This is well underway, and the outstanding work items now exclusively relate to integration with the map and localisation algorithm. Great care is taken to account for car park ramps, as by necessity, the low concrete walls are at their closest to the car at this moment. These ramps are considered to be the point of greatest risk as the localisation methods have to work extra hard when moving between floor levels. Also, the vehicle control algorithms need to account for gravitational acceleration of the car down the slope, and slowing it on the up-slope. After a lot of testing in simulation and more than 250 hours of in-car testing, we are pleased to have overcome this challenge, which you can see in action in the video below.
Develop the safety case and prepare for in-car-park trials. Safety documents to cover the testing thus far have been published. A final document to cover demonstrations with large numbers of people is the last item outstanding. We have secured initial agreement for a final demonstration in a different car park to showcase the functionality.
Engage with stakeholders to evaluate perceptions around AVP technology. We have engaged with the wider public around this technology and the results have been published.
The project recently held the 7th (of 10) quarterly review meetings where demonstrated the vehicle’s capabilities to the project steering committee and stakeholders.
The outstanding work items now exclusively relate to integration with the map and localisation algorithm, but we are confident of completing the project on time with our objective achieved. We are looking forward to the day this feature is available in a production vehicle!
Localisation is a central problem in robotics and it is very relevant to the AVP project. A self-driving car that is looking for an empty parking slot must know where it is on a map. For a precise manoeuvre, such as parking, an equally precise map and localisation algorithm are required.
The AVP project also has to respect a realistic budget for sensors, which rules out LiDARs in favour of cameras and IMUs. For this reason the project is committed to develop a vision-based localisation solution that uses HD Maps. Vision-based localisation however is very difficult and no one has yet demonstrated a system that works accurately and robustly in a fully general environment.
Within the International Standards Organisation, Technical Committee 204, Working Group 14, Parkopedia is part of a drafting team that is developing a standard for Automated Valet Parking Systems. The drafting team has agreed on the requirement for Artificial Landmarks, i.e. fiducial markers to be manually positioned in a carpark to enable accurate, robust localisation. At minimum, artificial landmarks are necessary around the pick-up and drop-off and zones to initialise the localisation system of a vehicle equipped with AVPS.
The next section will give an overview of localisation with landmarks.
Background to localisation with landmarks
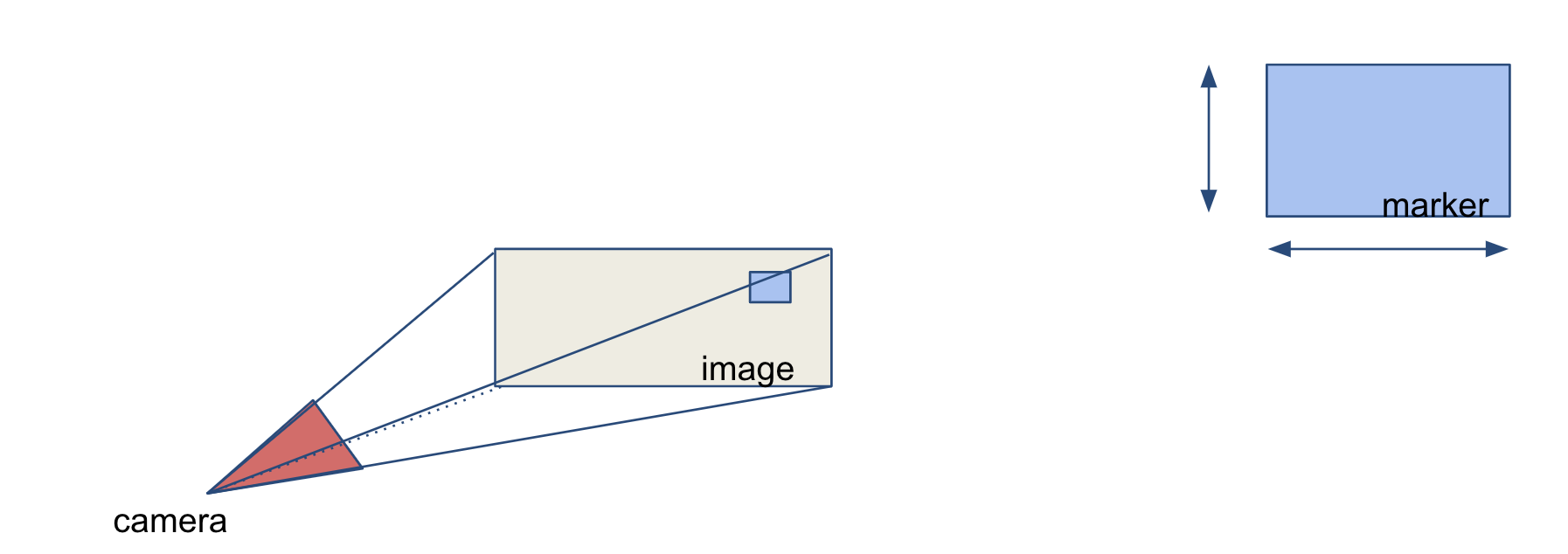
The first step of localisation with landmarks consists of detecting the landmark with the available sensors. In this example we are using a camera, so we need to find the pixel coordinates of a landmark in an image. Note that we use interchangeably the terms landmark and marker.
The second step is to estimate the sensor position with respect to the landmark. In the case of a calibrated camera and of a marker with known size, a single image is sufficient to estimate the rigid transformation between the camera and the marker. The algorithm used is a variation of Perspective-n-Point.
The third and last step is to estimate the pose of the camera in map frame. We know the position of the camera with respect to the marker from step 2. Provided that the marker is distinctively identifiable, we can find its position in the map. By chaining the two transformations, we obtain the desired pose of the camera in map frame.
Artificial Landmarks
There are many designs for artificial landmarks in literature.
Given the localisation process outlined in the previous section, we know some requirements for a good landmark. It must be easy to detect to facilitate the first step. It must be distinctive enough to be told apart from the other landmarks. And finally it has to be of a size and shape easy to handle in practice.
There is a convergence to a black and white square shape marker because its properties:
High contrast
Simple geometry
Easy to encode information
High contrast and square shape are clearly useful in detection because they can be exploited by established computer vision techniques. For example thresholding or line detection.
The information encoding part has more degrees of freedom that can be used differently, keeping in mind the goal of having highly distinguishable landmarks.
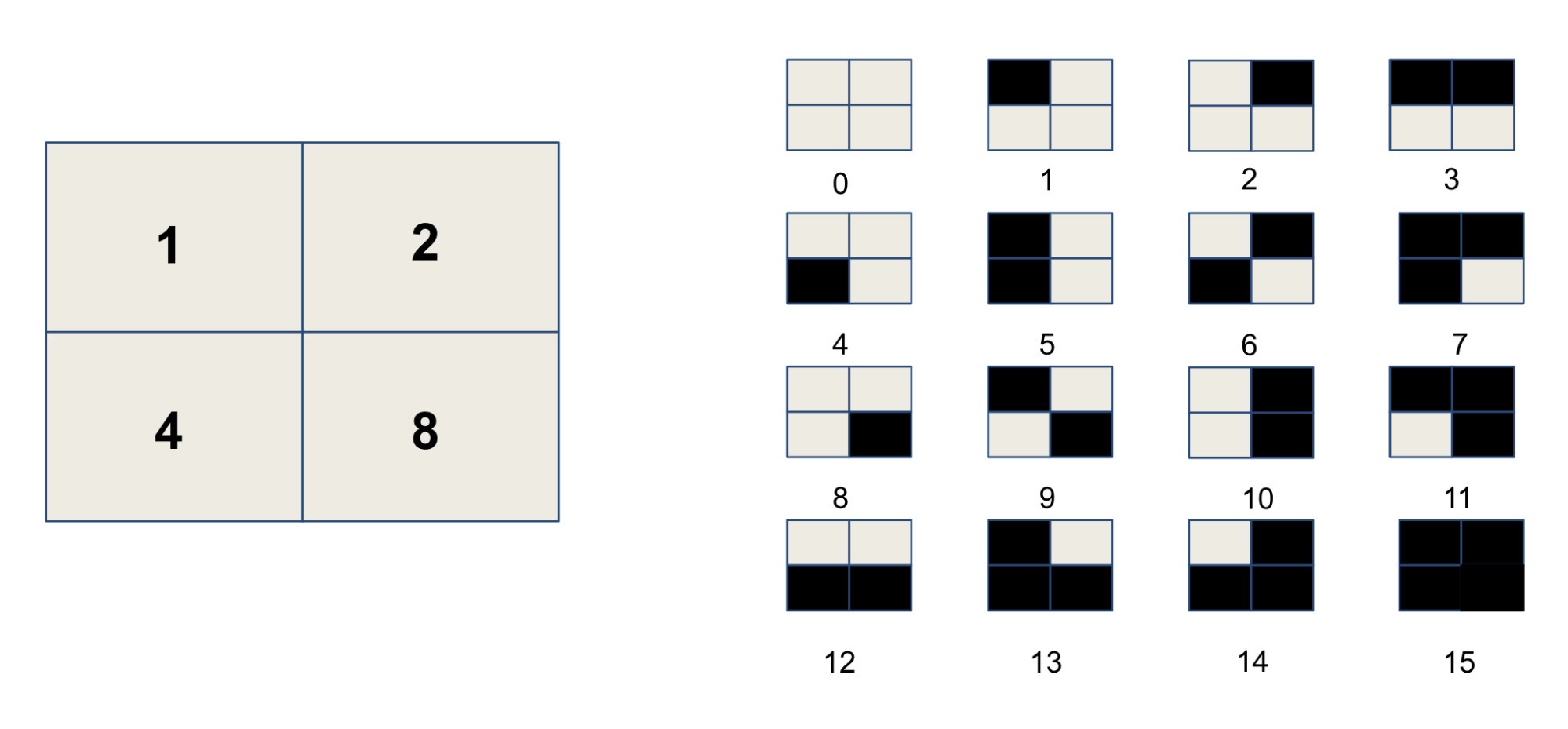
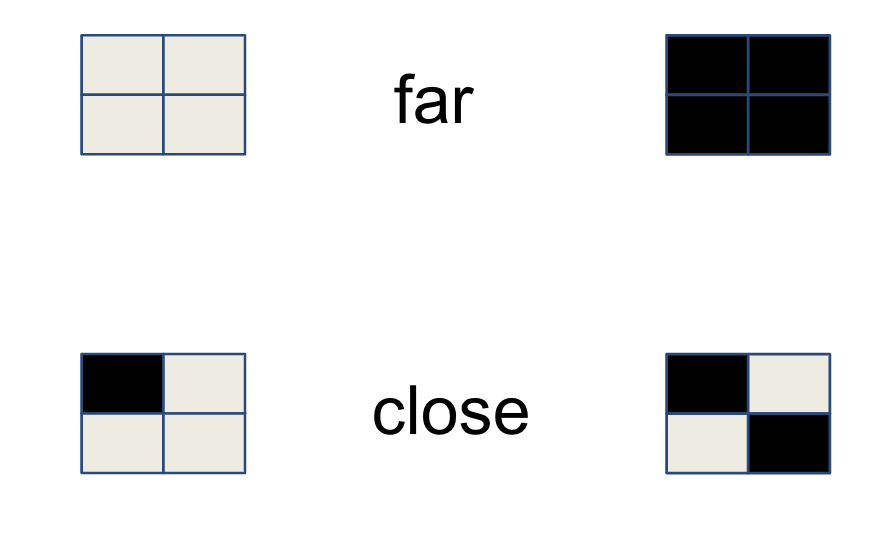
The basis of all the approaches is to subdivide the marker in a grid of small squares and use a binary encoding. That is to assign a power of two to each square, that is selected or not based on whether the square is black of white. By using a 2×2 grid we can represent 16 values as shown in the image below.
If we were to use all the possible markers for a given grid size, we would have the problem of erroneous detections. Some markers are very similar and minor occlusions or image noise could confuse the detection process. There are mainly two ways to deal with this problem, both of them based on the idea of sacrificing some information to achieve greater safety.
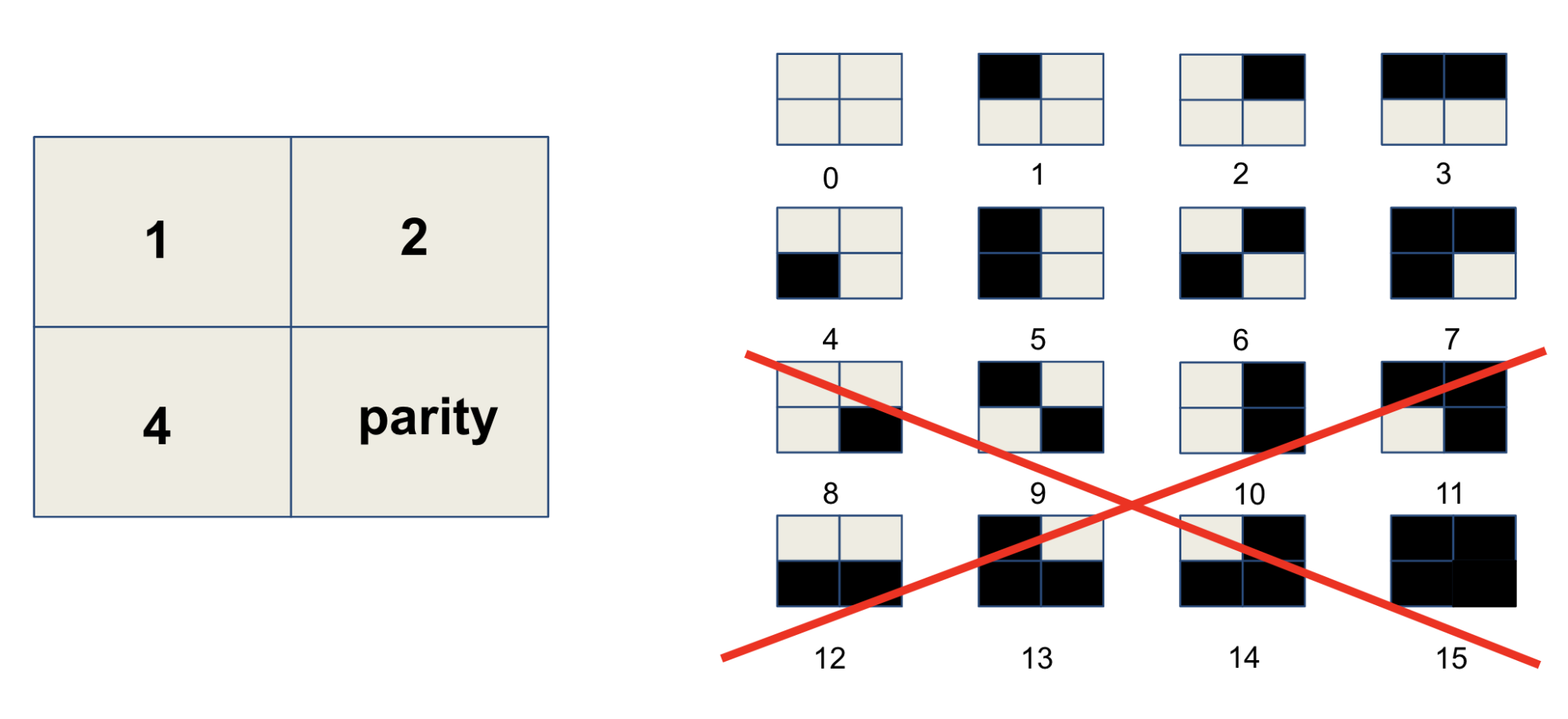
The first of these strategies is to set some squares to error detection. These squares convey no information on the id of the marker, but act as a necessary condition for correctness. The use of parity bits is widely studied in information theory and different schemes are available with different properties.
The second strategy is to maximize entropy, that is the distance between markers. Intuitively two markers with no square in common are far, while a marker is maximally close to himself. This notion is formalized by the concept of Hamming distance, which is also a widely studied topic in information theory.
The next two sections will analyze two marker types: ArUco and the standard proposed by the ISO drafting team.
ArUco markers
ArUco markers are a state of the art fiducial marker system explicitly designed for localisation.
The information encoding is designed for optimal intramarker distance. Possible markers are iteratively sampled and only the ones with a sufficiently large Hamming distance are selected.
ArUco is very flexible as it provides multiple dictionaries with different sizes. The authors of the paper provide a production grade implementation in OpenCV that also has Artificial Reality capabilities, very useful for debugging.
The following code snippet is an example of the use of a the Aruco library for localisation.
// Retrieve image of environment with Aruco marker cv::Mat input_image = /* retrieve image from camera */; // Initialise predefined dictionary DICT_4X4_250 auto dictionary = cv::aruco::getPredefinedDictionary(DICT_4X4_250); // Initialize MarkerVector struct, output parameter of the detection function MarkerVector markers; // Detect markers in the image cv::aruco::detectMarkers(input_image, dictionary, markers.corners, markers.ids); // Initialize camera intrinsics cv::Mat K = /* camera matrix */; cv::Mat D = /* distortion coefficients */; // Set marker size float marker_size = /* marker size including black border */ // Estimate marker pose cv::aruco::estimatePoseSingleMarkers(markers.corners, marker_size, K, D,markers.rotations, markers.translations);
We provide a downloadable with the PDF version of the ArUco dictionary DICT_4X4_250. An A2 version, more suitable for printing, is also provided for convenience. It is common to print the markers on waterproof PVC and mount them on 3mm plastic or aluminum.
ISO markers
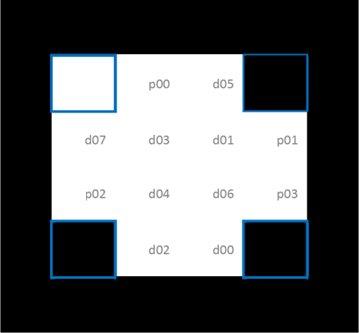
The AVPS drafting team has chosen to use a custom definition for artificial landmarks that explicitly encodes the orientation, data bits and parity bits for error checking. This encoding can be seen in the image below. Rotation is encoded through the four corner squares, with the top left white and remaining 3 black. With the orientation fixed, 8 data and 4 parity bits are encoded with the remaining 12 bits to create a Hamming Code.
It is possible to create custom dictionaries in OpenCV to use with the ArUco library. We have encoded the ISO dictionary as a custom one in a single header file which you can just include in your software.
Only one line of code from the previous example has to change – the creation of the dictionary – then the same code can be used to detect ISO markers.
auto dictionary = cv::makePtr<cv::aruco::Dictionary>(iso::generateISODictionary());
By using the library in this straightforward way, we see a lot of false positives, because we are not using the error correcting properties of the Hamming codes. A first step to improve the situation is to set the detector parameter errorCorrectionRate to zero, to disable the default correction done by ArUco. A better solution, that uses the full potential of the Hamming codes, requires to modify the ArUco detection algorithm.
As in the case of ArUco, we provide PDFs of the ISO dictionary as 30×30 cm squares and in A2 format.
Conclusion
A reasonable question to be asking right now is whether all this information above is even necessary. Can we not enable localisation without artificial landmarks?
It turns out that this is a difficult problem and industry is looking for a solution. The University of Surrey is developing a vision-based localisation algorithm that avoids the use of Artificial Landmarks as part of the AVP project and we look forward to demonstrate this technology on the AVP StreetDrone.
Expect to see a StreetDrone parking itself autonomously soon!
We are delighted to be publishing today the Safety Documents created to support the safe testing of the Automated Valet Parking function using the StreetDrone test vehicle in a car park.
This is the result of months of effort by Connected Places Catapult and Parkopedia. Following the post on Systems Engineering these documents now support the case made to drive under autonomous control within a car park.
These safety documents encompass system safety and operational safety.
The Safety Plan and the Requirements are live documents (they have been updated for testing in a car park and will be updated for future milestones)
Any entity seeking to conduct autonomous vehicle trials will need to develop and publish a safety case specific to their own trials (as specified by the government’s Centre for Connected & Autonomous Vehicles (CCAV) Code of Practice for Automated Vehicle Trialling) and gain permission to do so.
One of the main objectives of the AVP project is to create maps of car parks. Parkopedia is committed to working with our Open Source partners through the Autoware Foundation and have therefore released 3 maps of car parks to the community under the Creative Commons 4.0 BY-SA-NC license.
The maps are designed to be machine readable and are supplied in the OpenStreetMap XML format. This format is widely used and forms the basis for the OpenStreetMap mapsthat anyone can contribute to using tools such as the Java Open Street Map editor.
Our maps are designed to be useful for Automated Driving, which is why we’ve decided to make use of the Lanelet library as the data model for maps within the Autonomous Valet Parking prototype vehicle.
You can download the maps here and the following code can be used to plan a path using the lanelet library.
# libs
import lanelet2
import lanelet2.core as lncore
# load the map, for example autonomoustuff
osm_path = os.path.join(os.path.dirname(os.path.abspath('')), "AutonomouStuff_20191119_134123.osm")
print("using OSM: %s (exists? %s)" % (osm_path, os.path.exists(osm_path)))
# load map from origin
lorigin = lanelet2.io.Origin(37.3823636, -121.9091568, 0.0)
lmap = lanelet2.io.load(osm_path, lorigin)
# ... and traffic rules (Germany is the sole location, for now)
trafficRules = lanelet2.traffic_rules.create(lanelet2.traffic_rules.Locations.Germany, lanelet2.traffic_rules.Participants.Vehicle)
graph = lanelet2.routing.RoutingGraph(lmap, trafficRules)
# create routing graph, and select start lanelet and end lanelet for the shortest Path
startLane = lmap.laneletLayer[2797] # lanelet IDs
endLane = lmap.laneletLayer[2938]
rt = graph.getRoute(startLane, endLane)
if rt is None:
print("error: no route was calculated")
else:
sp = rt.shortestPath()
if sp is None:
print ("error: no shortest path was calculated")
else:
print [l.id for l in sp.getRemainingLane(startLane)] if sp else None
# save the path in another OSM map with a special tag to highlight it
if sp:
for llet in sp.getRemainingLane(startLane):
lmap.laneletLayer[llet.id].attributes["shortestPath"] = "True"
projector = lanelet2.projection.MercatorProjector(lorigin)
sp_path = os.path.join(os.path.dirname(osm_path), os.path.basename(osm_path).split(".")[0] + "_shortestpath.osm")
lanelet2.io.write(sp_path, lmap, projector)
# now display in JOSM both, and you can see the path generated over the JOSM map
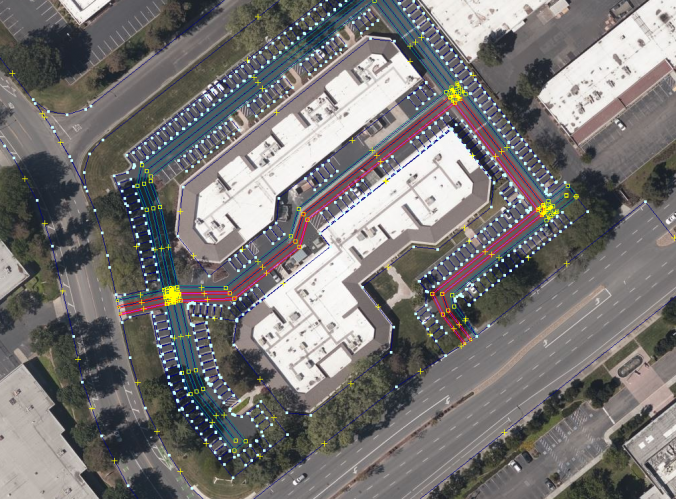
# Ctrl+F --> type:relation "type"="lanelet" "shortestPath"="True"
# and the path will be highlighted as the image below
The Autonomous Valet Parking project is a 30-month project funded by InnovateUK and the Centre for Connected and Autonomous Vehicles, due to end on 31 October 2020. We are five quarters in and a lot has been achieved:
We have created our first maps of car parks which we are trialling with customers,
The vision-based localisation algorithms are well advanced,
The autonomous software to power our StreetDrone is ready to take out for a demo,
The safety case has ensured that we are in a position to demo this safely.
At the CENEX-CAM event that took place at Millbrook Proving Ground UK 4-5 September 2019, we showed the progress made in the project at this halfway point. The main objective was to demonstrate that the Autoware-based software on the StreetDrone is able to control the vehicle by following waypoints consistently and accurately. The demonstration scenario consisted of three parts and reflects how we believe AVP will be used in real life. In the demo, you can see:
The vehicle following a pre-defined set of waypoints to the designated parking spot, having been dropped off at a designated drop-off zone by its driver,
The vehicle exiting the parking spot and driving to the pick-up zone (where the vehicle’s regular driver would collect it),
A test of our automatic emergency braking, using the front-centre ultrasonic sensor on the vehicle.
This public demo was an important milestone for us to demonstrate our ability to control the vehicle using a PID controller for longitudinal (throttle) control and pure-pursuit for lateral (steering) control.
Localisation is done using the LiDAR with NDT matching. At this stage of the project we’ve limited the speed to 1m/s, this will double to 2m/s (5mph) in the future.
We are using the SAE convention for marking lamps, with green for manual control, blue when under autonomous control and red when an error state occurs. Adding the RGB LED lighting was done alongside the development work to enable switching between forwards and reverse in software while still in autonomous mode.
The safety case for the project combines operational and system safety. On the operational side we have a safety driver who can take over when a dangerous situation presents, and we also have system safety using the LiDAR and ultrasonic sensors, which will bring the vehicle to a stop to avoid driving into a hazard. We demonstrated Automated Emergency Braking using the ultrasonic sensor, following the testing and preparation done previously at Turweston.
Overall, the demo (done five times in two days) was well received, and we saw good levels of interest from delegates at the event, with lots of questions being asked about the project. It was a pleasure to speak to media and to delegates.
We’ve learned a lot from our friends at Ordnance Survey and we look forward to hosting them and others at the upcoming Autoware Hackathon. Many thanks to them of all the help and for storing our StreetDrone overnight under their gazebo!
Over the remaining 13 months of the project, we will be working on navigation and localisation using maps, with a final demonstration of the end solution due to take place in Autumn 2020.
You know how it can be a real challenge to understand the complexity in emerging multi-modal and automated transport systems?
By harnessing Systems Engineering best practices, our Systems Engineers at the Connected Places Catapult (CPC) use their expertise in systems requirements gathering, safety management, and verification and validation, ensuring that all aspects and interactions in the AVP system are clearly defined, integrated, evaluated and tested, thus improving our ability to deliver a safe, efficient and innovative system.
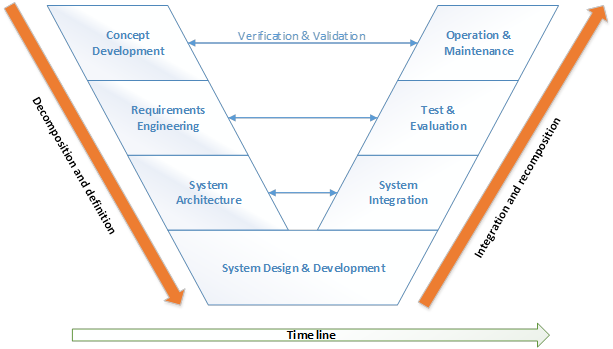
Systems Engineering is an established practice capable of delivering technically complex systems, and Systems Engineers swear by the V lifecycle model, which shows the logical relationship between the different System Engineering activities.
In the V model, time and system maturity proceed from left to right:
System Engineering “V” diagram
In each stage of the system life cycle, the Systems Engineering process iterates to ensure that a concept or design is feasible, and that the stakeholders remain supportive of the solution as it evolves.
The process is applied sequentially, one level at a time, adding additional detail and definition with each level of development.
1. Concept Development
The concept development is the first step of the life cycle of the AVP project. This stage explores concepts, identifies stakeholders’ needs and proposes viable solutions.
Requirements definitions are the key to success in the design and development of any complex system. Our Systems Engineers have carefully elicited requirements from all the project stakeholders to ensure the final product meets everyone’s needs, from technical feasibility to budget considerations and testability.
The total set of requirements encompasses the functional, performance, and non-functional requirements and the architectural constraints.
3. System Architecture
The architecture of a system is its fundamental structure. The purpose of drawing an architecture is to define a comprehensive solution based on principles, concepts, and properties logically related and consistent with each other. The architecture defines the system boundary and functions, from which more detailed system requirements can be derived.
This
step of the cycle is focused on developing:
• System
Level Architecture
• Functional
Architecture
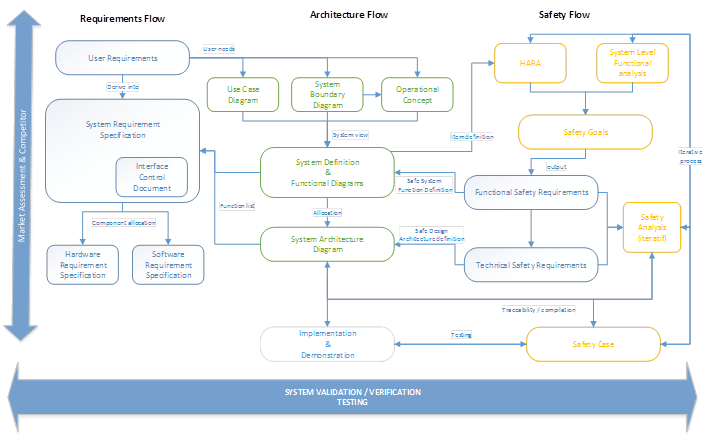
At the start of the AVP project, both of these architectures were drawn. The system level architecture refers more to the overall system and its operating environment. The functionalities that enable the AVP technology are mapped on the functional architecture, based on the Autoware ROS and showing modules such as perception, sensor fusion, path planning, and others.
4. System design and development
Once the initial opportunities and constraints have been identified in the steps above, it is time to create and describe in detail the AVP system to satisfy the identified needs.
While the Parkopedia Engineers work on developing the AVP system in accordance with the ConOps, Requirements and System Architecture, the Systems Engineers at the CPC focus on the functional system analysis and producing the Safety Case for the AVP testing.
This lifecycle step expands on ISO 26262, which addresses the functional safety in road vehicles. The analysis of the system level safety is carried through system-level functional analysis, such as the Failure Mode and Effect Analysis (FMEA) and the Hazard Risk Assessment (HARA) , which results in providing the system safety goals (translated as the safety requirements for the system). These form the system safety argument for the Safety Plan for the AVP project. This step is crucial to ensure the risk is minimised if and when the system fails. Every malfunction leads to a warning and degradation strategy and the safety driver should be able to gain control of the vehicle.
Note: the system analysis also involves reviewing all of the previous deliverables as the design is being developed.
5. System Integration
The AVP system is made of different system elements provided by different parties: – The vehicle is provided by StreetDrone – The software, application and maps are provided by Parkopedia – The localisation system is developed by the University of Surrey
This step ensures that all of the disparate system elements integrate to create an effective whole and allows the different teams to work in parallel confident that all of the pieces fit and work together. The interface management activity relate to the steps taken to integrate the different architecture elements:
Reviewing and refining the previously mentioned deliverables (ConOps, System Architecture, Requirements, FMEA, HARA)
Assessing the criteria and methods for Requirements verification and validation (Analysis/Inspection/Test/Demonstration)
The Interface Control Document (ICD), which describes the integration strategy of the AVP system. This is a live document and is continuously updated until the end of the system development and testing.
6. Test & Evaluation
Prior to driving in the desired environment, the vehicle has to demonstrate that it is capable of safely navigating and responding to diverse situations and scenarios, such as emerging pedestrians, vehicles, obstacles, etc. By combining simulation and testing in a real environment (open field track and car parks), the AVP system can be validated.
This step focuses on ensuring that the developed system is operationally acceptable and that the responsibility for the effective, efficient, and safe operations of the system is transferred to the owner.
Can the system be tested, demonstrated, inspected, or analysed to show that it satisfies requirements?
Are the requirements stated precisely to facilitate specification of system test success criteria and requirements
Testing will always be performed with a highly trained safety driver, who will monitor the vehicle behavior at all times and ready to take over in the event of a failure. An engineer will monitor the path on a HMI, so that the safety driver is not distracted. The system must be able to detect and respond to a wide range of static obstacles in the testing environment.
It examines the evidence required to show that acceptable safety has been achieved for any given testing activity, and how that evidence is to be collected, such that when all the evidence is taken together, there is a convincing argument that the project as a whole is safe.
Safety Case
It summarises the evidence collected prior to commencing Autonomous Valet Parking testing in accordance with the Safety Plan. There will be a Safety Case for each test phase: testing in a controlled environment (open field track), testing in car parks and the demonstration.
RAMS:
This document sets out the safety procedures that all participants are required to follow during testing of the autonomous control system and ensures the requirements and procedures are read and understood by all involved in the trial, and adhered to at all times. The Risk Assessment for the trial is also included in this document. Similarly to the Safety Case, each testing phase will be prepared with a RAMS.
After testing, the requirements are reviewed and given a pass/fail mark depending on the acceptance criteria set. In both cases, a justification needs to be provided.
Once again, the previous deliverables are reviewed and refined as required.
7.Operation and maintenance
The AVP system has now been tested in different test environments and settings. The system is ready to be deployed, and as part of this activity, several demonstrations are organised as evidence of the operational effectiveness of the deployed AVP system.
The Systems Engineers carry the below activities, verifying and validating the concept one last time:
RAMS
Safety Case close out
Verification and Validation close out
Review and refine as required previous deliverables
Systems Engineering Process Flow Diagram
8. Conclusion
The self-driving car industry is a fast-moving and uncertain environment, which makes safety the number one priority. This is also why the AVP project consortium is encouraging the industry to work together, collaborate, share use-cases and lessons learnt. Self-driving cars have the potential to ensure safety of passengers, reduce road congestion, drive smarter and in a more sustainable way. By implementing a robust Systems Engineering process, the self-driving car industry can mitigate risks and drive society safely into the future.
IV2019 brings together researchers and practitioners from universities, industry and government agencies worldwide to share and discuss the latest advances in theory and technology related to intelligent vehicles.
The Autoware foundation is hosting a workshop on Sunday 9th June 2019, with the aim of discussing the current state of development of Autoware AI and Autoware Auto, and considering various technical directions that the Foundation is looking to pursue. Parkopedia’s contribution is around maps and specifically, the integration of indoor maps for Autonomous Valet Parking.
Parkopedia’s Angelo Mastroberardino will be presenting our work on maps, answering questions like “Why do we need these maps?”, “How do we represent geometry and road markings within maps?”, and naturally leading towards the question of how we use these maps for path planning within indoor car parks.
Later, Dr Brian Holt will be joining Tier 4, Apex.AI, Open Robotics, TRI-AD, and Intel on a panel to discuss Autoware and its impact on autonomous driving.
Parkopedia joined the Autoware Foundation as a premium founding member, because we believe in open source as a force multiplier to build amazing software. We are contributing maps, including for the AutonomouStuff car park in San Jose, USA, which you can download for use with your own self-driving car in simulation. Find out more
Connected Places Catapult (CPC) have conducted research with
UK car drivers and stakeholders to better understand public and industry readiness
for autonomous valet parking (AVP).
The key questions guiding the research were:
What are the key parking pain points that can be
resolved by AVP?
What are other likely benefits of AVP to users
and parking stakeholders?
What are the key barriers to AVP deployment and
uptake, from a social and behavioural point of view?
What will be the likely impact of AVP, on the
environment, the economy, and the parking industry?
The report produced details the findings, conclusions and
recommendations from a suite of research activities:
A literature review to explore existing
knowledge about the chosen research topics and questions;
Stakeholder interviews with parking
professionals and OEMs to explore their views of AVP;
Focus group interviews to explore the needs and
attitudes of drivers in-depth; and
A UK wide survey of 1025 car drivers to examine
differences between user groups, and to gauge how common certain attitudes or
needs are.
The research found that car drivers would be more receptive
to the car taking control in a car park than on the roads and a technology
solution that can reduce the stress of parking and make parking easier would be
appealing. One in five drivers would like to use AVP now with a further 40%
open to the idea but wanting to know more about it. Likely early adopters would
be younger male drivers and those who have previously used driver assistance
technology or have previously used a valet parking service.
































Recent Comments